
计组与微机控制
7.0 x86指令系统和一些后期展望
7.0 x86指令系统和一些后期展望
之前开过ARM指令系统,这一章我们就快快过一下X86指令系统,之后我们回到之前的总线和异常中断章节,预估第八章是总线,第九章异常中断,之后第十章IO接口,第十一章程序设计和简要的STM32F407之后,我们就完结撒花进入STM32实战keil5和cubeMX篇,再进入PID控制和RTOS,之后回openmv精进算法和开新章节神经网络深度学习。
之后还会开一个单独的章节算法与数据结构和leetcode对应的训练,以及背板手操SPI总线,UART通讯,卡尔曼滤波调参
以及电路仿真设计,还有PCB设计章节,和之前的全栈以及vibe小练习。
机器指令和汇编指令
计算机真正执行的不是 MOV AX, BX 这种英文形式,而是二进制机器码。
比如:MOV AX, BX
最后会被汇编器翻译成一串机器码。
汇编指令:给人看的符号形式机器指令:给 CPU 看的二进制形式
例如:MOV AH, [BX + DI + 50H]
人看起来能理解,但 CPU 不能直接理解这个文本。
汇编器会把它翻译成类似:8A 61 50H
这种机器码,CPU 才能执行。
一、8086/8088 指令编码
这一节讲的是:8086/8088 的一条指令在机器码里是怎么组成的。
8086/8088 采用变长指令格式(ARM采用risc固定4字节32位)
8086/8088 的指令不是固定长度的。
课本说:一条指令可以由 1 ~ 6 个字节组成
这叫 变长指令格式。为什么要变长?
因为不同指令需要表达的信息不一样。比如:CLC
这种指令很简单,只要告诉 CPU“清进位标志 CF”即可,可能一个字节就够。
但下面这种指令复杂得多:
MOV AH, [BX + DI + 50H]
它要告诉 CPU:要执行 MOV 目标是 AH源操作数在内存中内存地址由 BX + DI + 50H 形成操作数是字节 信息多了,机器码自然更长。
所以 8086/8088 用变长指令,可以做到:
简单指令短一些,节省空间复杂指令长一些,表达更多信息
二、一条双操作数指令大致由 4 部分组成
课本用双操作数指令举例,机器码格式大致包括:
操作特征部分 寻址特征部分位移量部分 立即数部分
可以理解成:这条指令要干什么? 操作数在哪里?地址要不要加位移量? 有没有直接给出的常数?
三、操作特征部分:OP code、d、w
操作特征部分通常在指令编码的第一个字节中。

它包含:OP code d w
1. OP code:操作码
OP code 就是 operation code,操作码。
它说明:这条指令要做什么操作比如:MOV ADD SUB OR
这些不同操作,对应不同的操作码。
所以 OP code 是机器指令的核心。 OP code 决定“干什么”
2. d 字段:数据传送方向
d 是 direction,方向位。很多双操作数指令有两个操作数:
MOV 目的, 源 ADD 目的, 源 SUB 目的, 源
在机器码里,常有一个操作数由 reg 字段指定,另一个操作数由 mod 和 r/m 字段指定。
那问题来了:到底谁是源操作数,谁是目的操作数?这就由 d 字段决定。
课本说:d = 1:目的操作数由 reg 字段确定 d = 0:源操作数由 reg 字段确定
d = 1:reg 是目的d = 0:reg 是源
如果机器码表示的是:
reg 字段 = AHr/m 字段 = [BX+DI+50H]
当:d = 1
意思就是:MOV AH, [BX+DI+50H]
因为 reg 指定的 AH 是目的操作数。
当:d = 0
意思就可能变成:MOV [BX+DI+50H], AH
因为 reg 指定的 AH 是源操作数。
所以 d 位主要解决:数据从哪儿来,到哪儿去
3. w 字段:字节操作还是字操作
w 是 word 的意思,用来说明操作数宽度。
w = 1:字操作,16 位w = 0:字节操作,8 位 例如:MOV AX, BX
AX、BX 是 16 位寄存器,所以是字操作:w = 1
而:MOV AL, BL AL、BL 是 8 位寄存器,所以是字节操作:w = 0
这个非常重要,因为同样的 reg 编码,在 w 不同时表示的寄存器也不同。
七、寻址特征部分:mod、reg、r/m
第二个字节通常包含:mod reg r/m
它们合起来告诉 CPU:
操作数在哪里怎么计算内存地址用哪个寄存器
八、mod 字段:寄存器还是内存?有没有位移量?
mod 字段有 2 位。
mod | 含义
00 | 存储器寻址,无位移量
01 | 存储器寻址,有 8 位位移量
10 | 存储器寻址,有 16 位位移量
11 | 寄存器寻址,无位移量简单说:
mod = 11:操作数在寄存器里mod ≠ 11:操作数在内存里
如果操作数在内存里,mod 还要说明有没有位移量:
mod = 00:没有位移量mod = 01:有 8 位位移量mod = 10:有 16 位位移量
位移量就是地址公式里额外加上的常数,比如:
[BX + DI + 50H]
这里的:50H就是位移量。
九、reg 字段:指定寄存器
reg 字段有 3 位,可以表示 8 种寄存器。
但它具体表示哪个寄存器,要看 w。课本表 4.2:
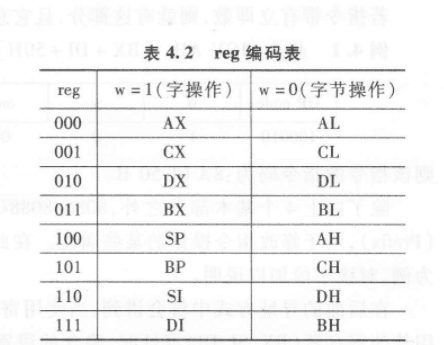
注意这个表很重要。比如:
reg = 100 如果:w = 1
它表示:SP
如果:w = 0
它表示:AH
所以不要只看 reg 三位,还要结合 w。
十、r/m 字段:寄存器或内存地址形式
r/m 也有 3 位。它受 mod 控制。
如果: mod = 11
那么 r/m 表示寄存器,规则和 reg 类似。
如果: mod ≠ 11
那么 r/m 表示内存操作数的有效地址 EA 怎么计算。
十一、有效地址 EA 是什么?
EA 是 Effective Address,有效地址。
它指的是:段内偏移地址
不是最终物理地址。比如:
MOV AX, [BX + SI + 100H]
其中:EA = BX + SI + 100H
如果默认段寄存器是 DS,那么物理地址是:DS × 10H + EA
所以:EA 是偏移地址 物理地址 = 段基址 + EA
十二、r/m 和 mod 组合出的内存地址形式
当 mod ≠ 11,也就是内存寻址时,r/m 和 mod 组合决定 EA 公式。
先看没有位移量的情况:
如果 mod=01,就是这些公式再加 8 位位移量:
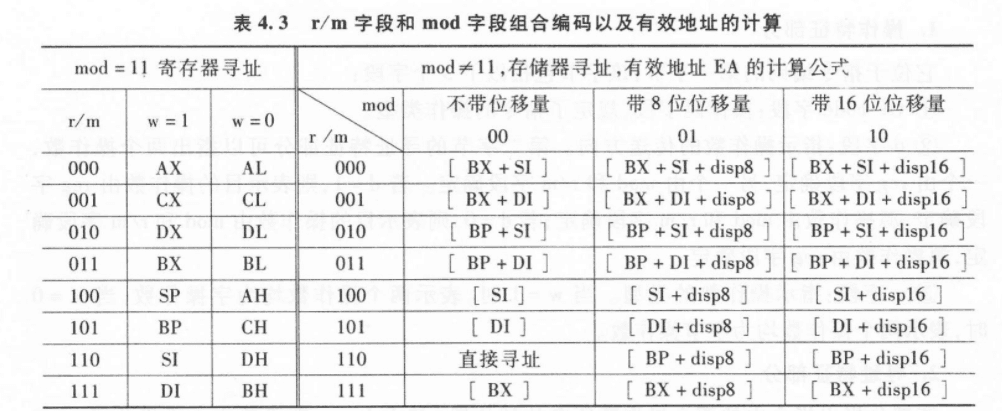
[BX + SI + disp8][BX + DI + disp8][BP + SI + disp8]...
如果 mod=10,就是加 16 位位移量:
[BX + SI + disp16][BX + DI + disp16][BP + SI + disp16]...
特别注意:mod=00, r/m=110
不是 [BP],而是 直接寻址。
也就是指令后面直接给出一个 16 位偏移地址。
而:
mod=01, r/m=110mod=10, r/m=110
才表示:
[BP + disp8][BP + disp16]
这个很容易考。
十三、8086 双操作数指令不能两个操作数都在内存
课本说 IBM PC 规定:
双操作数指令中,至少有一个操作数在寄存器中两个操作数不能同时在存储器中
比如:MOV AX, [1000H]
可以,因为一个操作数 AX 在寄存器里。
MOV [2000H], AX也可以,因为 AX 在寄存器里。
但:MOV [2000H], [1000H]
不可以,因为两个操作数都在内存里。
CPU 一般不能直接“内存到内存”传送,通常要通过寄存器中转:
MOV AX, [1000H] MOV [2000H], AX
这点后面写汇编非常重要。
十四、位移量部分
位移量 displacement 是有效地址的一部分。
比如:MOV AH, [BX + DI + 50H]
这里:EA = BX + DI + 50H
其中:50H就是位移量。
位移量是否存在,由 mod 和 r/m 决定。
如果 mod=01:有 8 位位移量
如果 mod=10:有 16 位位移量
如果 mod=00:通常没有位移量
但有一个特殊情况:mod=00, r/m=110
此时使用直接寻址,指令后面有一个 16 位地址。
十五、立即数部分
立即数 immediate 是直接写在指令里的常数。
比如:MOV AX, 1234H
其中:1234H就是立即数。
立即数一般放在机器码最后,可以是 1 个字节,也可以是 2 个字节。
注意小端存放:MOV AX, 1234H
立即数在机器码里通常按:34H 12H存放。
低字节在前,高字节在后。
十六、例 :MOV AH, [BX + DI + 50H]课本给的例子是:
MOV AH, [BX + DI + 50H]
1. 先看操作
这是 MOV 指令。含义:把内存单元中的一个字节送到 AH
为什么是字节?因为 AH 是 8 位寄存器。
所以:w = 0
2. 方向 d
目标是 AH。AH 是由 reg 字段指定的。
所以:d = 1 表示 reg 字段指定目的操作数。
3. reg 字段
AH 在表 4.2 中,当 w=0 时: AH 对应 reg = 100
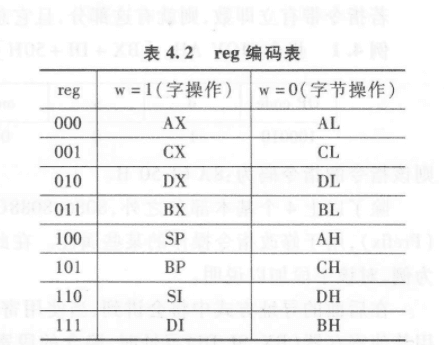
4. 内存地址 [BX + DI + 50H]
有效地址:EA = BX + DI + 50H [BX + DI] 对应r/m = 001
有 8 位位移量 50H,所以:mod = 01
5. 拼机器码
课本给出:OP code = 100010 d = 1 w = 0
第一字节:10001010B = 8AH
第二字节:mod = 01 reg = 100 r/m = 001
合起来:01100001B = 61H
位移量:50H
所以机器码是:8A 61 50H
不用一开始就能开始完整编码,但要看懂:
8A:说明 MOV、方向、字节/字61:说明 AH 和 [BX+DI+disp8]50:位移量
十七、段超越前缀 Prefix
正常情况下,内存寻址有默认段寄存器。
比如:MOV AX, [BX] 默认用:DS
也就是:DS:[BX]
但有时候你想不用默认 DS,而是强制用 ES、CS、SS 等,就要使用段超越前缀。
比如:MOV AX, ES:[BX]
意思是:从 ES 段中偏移地址 BX 的位置取一个字送入 AX
1. 段前缀编码
课本给出的段前缀格式是:001 sreg 110
其中 sreg 表示段寄存器:
sreg | 段寄存器
00 | ES
01 | CS
10 | SS
11 | DS所以常见段超越前缀机器码是:
段寄存器 | 前缀机器码
ES | 26H
CS | 2EH
SS | 36H
DS | 3EH2. 例 4.2:MOV AX, ES:[BX]
指令:MOV AX, ES:[BX] 如果没有 ES:,默认是:MOV AX, [BX]
也就是从 DS 段取。
但这里用了 ES 段超越,所以机器码前面要加 ES 前缀:26H
后面的:MOV AX, [BX]
对应机器码:8B 07H
所以整条指令机器码是:
26 8B 07H
这里:26:ES 段超越前缀 8B 07:MOV AX, [BX]
十八、4.1.2:指令执行时间
这一节讲:一条指令执行到底要花多少时间。
一条指令的执行时间由几个阶段组成:
取指令 取操作数 执行指令 传送结果
但是 IBM PC 采用预取指令方式,所以取指令时间和执行时间可能重叠。
因此通常估算时重点看:基本执行时间 取/存操作数时间计算有效地址 EA 的时间
十九、不同指令执行时间差别很大
比如:ADD 寄存器到寄存器:3 个时钟周期MOV 寄存器到寄存器:2 个时钟周期I MUL 整数乘法:128 ~ 154 个时钟周期I DIV 整数除法:165 ~ 184 个时钟周期条件转移不转移:4 个时钟周期条件转移发生转移:16 个时钟周期
这说明:加法、传送很快 乘法、除法很慢跳转是否发生也会影响时间
这和现代 CPU 也类似:加法很便宜,除法很贵,分支会影响流水线。
二十、同一条指令,不同寻址方式时间也不同

这里 EA 不是地址,而是:计算有效地址所需时间 为什么寄存器到寄存器最快?
因为操作数都在 CPU 内部,不用访问内存。
为什么内存相关慢?因为要通过总线访问存储器。
所以后面写汇编时,一个基本优化思想是:
能用寄存器就尽量用寄存器 减少内存访问
二十一、EA 计算也要花时间
表 4.6 列出不同寻址方式计算 EA 的时间。
大致趋势是:直接寻址:6 寄存器间接:5寄存器相对:9 基址变址:7~8 相对基址变址:11~12
为什么复杂寻址更慢?因为 CPU 要多做加法。比如:[BX]
EA 只等于 BX。
而:[BX + DI + 100H]
EA 要算:BX + DI + 100H
二十二、5MHz 时钟下怎么换算时间?
假设时钟频率是 5MHz。周期时间:1 / 5MHz = 0.2 μs
如果一条指令需要 3 个时钟周期:t = 3 × 0.2 = 0.6 μs
如果:ADD 存储器到寄存器 时间 = 9 + EA
假设 EA = 12:总周期 = 21时间 = 21 × 0.2 = 4.2 μs
所以同样是 ADD:ADD AX, BX
可能只要 0.6 μs。而:ADD AX, [BX + DI + 100H]就可能慢很多。